Documents are of little importance, but documenting is essential.
Documents are valuable but costly. How many documents should we have? "Less is more". How less is enough?
You will need more documents until you can synchronize your team.
So, how many is enough?
It depends on the culture, quality, workflow of your team, and mutual understanding between members. The less stable your team, the more documents you need.
2019/10/26
2019/04/24
2019白沙屯媽進香後記

跟白沙媽進香最大的副作用
不是曬傷脫皮
不是筋骨痠痛起水泡
不是指甲掀開脫落
不是曬傷脫皮
不是筋骨痠痛起水泡
不是指甲掀開脫落
而是哭點變得超低
看到神轎很超脫自己想法時想哭
看到香丁腳們彼此扶持時想哭
看到沿途鄉親堅持把各種資源塞進你手中時想哭
…
看到香丁腳們彼此扶持時想哭
看到沿途鄉親堅持把各種資源塞進你手中時想哭
…
我以為只我有這副作用
午休跟其他香丁腳聊起,發現很多人都是這樣
也因為這副作用
大家雖然走到很想#@$*&%!#
可是隔年大家都失憶
乖乖又自動報到了
大家雖然走到很想#@$*&%!#
可是隔年大家都失憶
乖乖又自動報到了
唉…沒藥醫
2019/04/23
2019/01/16
以Python程式產生InfluxDB資料
我們接下來將寫個Python程式,來模擬溫度sensor產生資料並寫入InfluxDB中。然後利用這些資料,在Chronograf中設定dashboard的樣式。
要讓Python連上InfluxDB,我們需要Python-InfluxDB connection。我們可以使用pip來安裝這個connection元件:"pip install influxdb"。詳細指令介紹可參考這一頁。(此範例使用的是Python 3.x)
接下來的程式是模擬廚房、臥室、客廳三個溫度感應器,每秒鐘會回報溫度到InfluxDB。程式一開始,會先建立與InfluxDB server的連結,並建立一個 "sample"的database。我們準備了一個obj的json物件樣板。大家可以把measurement想像成表格(table)名稱。這裡有兩個columns,一個是location用來存放感應器位置,另一個是value來存放溫度。前面有提過,tag是indexed column,field是non-indexed column。由於InfluxDB是時間序列資料庫,因此每筆資料都隱含了一個time的column。
開始執行此Python程式後,就可以看到InfluxDB視窗一直有log message在跑,如果沒有error message,就表示此python程式正在餵資料到InfluxDB。
Python-InfluxDB connection元件的相關資料,可參考這頁的說明。
我們可以把InfluxDB client開啟,打入下列指令,來看最近三秒寫入InfluxDB的資料,確認資料確實有寫入。從這裡我們也可看到,除了location與value這兩個我們設定的欄位外,還有一個time欄位。

接著我們再用瀏覽器進入Chronograf網頁介面。(http://localhost:8888)
我們到Dashboard這頁,可以看到下面的畫面。

點選line,然後add data,接下來都可以用點選的方式來產生dashboard圖樣。我們先產生一個彙總的圖表。點選sample,再點選temperature,把三個地點都勾起來,並點選group by location,然後再把value勾起來。這個操作過程會自動幫我們產生InfluxQL。完成後點選右上角的綠色勾即可儲存。

回到Dashboard頁面,可以設定此圖表之位置與大小,並可在右上角設定更新速度與資料顯示長度。

正上方有Add a Cell to Dashboard藍色按鈕,可以加入更多圖表。大家可以去玩玩各種圖表,了解Chronograf。Chronograf的使用說明可以參考官網的文件。

要讓Python連上InfluxDB,我們需要Python-InfluxDB connection。我們可以使用pip來安裝這個connection元件:"pip install influxdb"。詳細指令介紹可參考這一頁。(此範例使用的是Python 3.x)
接下來的程式是模擬廚房、臥室、客廳三個溫度感應器,每秒鐘會回報溫度到InfluxDB。程式一開始,會先建立與InfluxDB server的連結,並建立一個 "sample"的database。我們準備了一個obj的json物件樣板。大家可以把measurement想像成表格(table)名稱。這裡有兩個columns,一個是location用來存放感應器位置,另一個是value來存放溫度。前面有提過,tag是indexed column,field是non-indexed column。由於InfluxDB是時間序列資料庫,因此每筆資料都隱含了一個time的column。
開始執行此Python程式後,就可以看到InfluxDB視窗一直有log message在跑,如果沒有error message,就表示此python程式正在餵資料到InfluxDB。
from influxdb import InfluxDBClient
import random
import time
host = "localhost" #influxdb IP
port = 8086 #influxdb port
username = "root" #influxdb username
password = "root" #influxdb password
dbname = "sample" #database name
# json object template
obj = {'measurement':'temperature', 'tags':{'location':''}, 'fields':{'value':0}}
# arrays for location names and temperatures
locations = ['kitchen', 'bedroom', 'living room']
t = [20] * len(locations)
client = InfluxDBClient(host, port, username, password) # connect influxdb
client.create_database(dbname) # create database
while True:
for i in range(0,len(locations)):
t[i] = round(t[i] + random.uniform(-0.5, 0.5), 2) # generate temperature
# prepare data object
obj['tags']['location'] = locations[i]
obj['fields']['value'] = t[i]
print(obj)
# write data to influxdb
client.write_points([obj], 'ms', dbname)
time.sleep(1)
Python-InfluxDB connection元件的相關資料,可參考這頁的說明。
我們可以把InfluxDB client開啟,打入下列指令,來看最近三秒寫入InfluxDB的資料,確認資料確實有寫入。從這裡我們也可看到,除了location與value這兩個我們設定的欄位外,還有一個time欄位。

接著我們再用瀏覽器進入Chronograf網頁介面。(http://localhost:8888)
我們到Dashboard這頁,可以看到下面的畫面。

點選line,然後add data,接下來都可以用點選的方式來產生dashboard圖樣。我們先產生一個彙總的圖表。點選sample,再點選temperature,把三個地點都勾起來,並點選group by location,然後再把value勾起來。這個操作過程會自動幫我們產生InfluxQL。完成後點選右上角的綠色勾即可儲存。

回到Dashboard頁面,可以設定此圖表之位置與大小,並可在右上角設定更新速度與資料顯示長度。

正上方有Add a Cell to Dashboard藍色按鈕,可以加入更多圖表。大家可以去玩玩各種圖表,了解Chronograf。Chronograf的使用說明可以參考官網的文件。

InfluxDB
若想了解時間序列資料,可參考這篇簡述。
InfluxDB應該是目前佔有率最高的TSDB了,因此我們利用InfluxDB來了解TSDB的運作。
這裡是InfluxData的官網,其open source的版本中有一個TICK stack的架構,包含了四個元件:
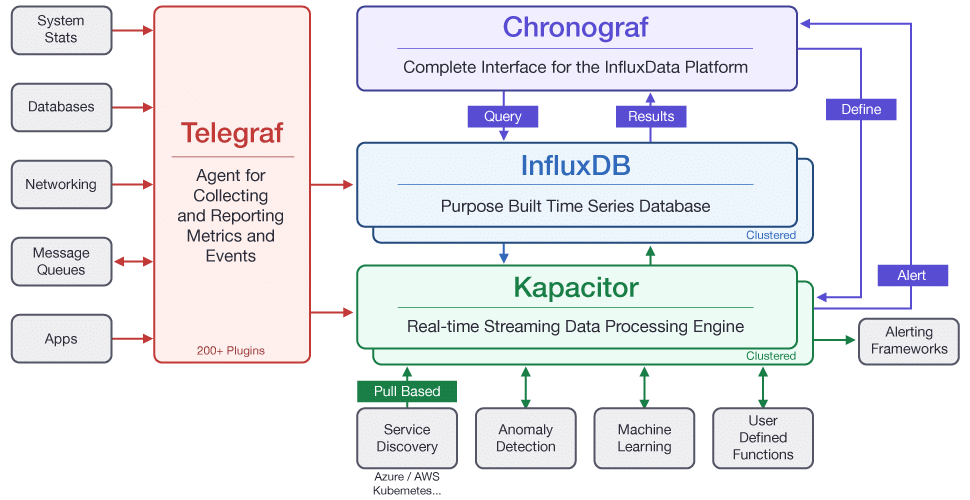





InfluxDB應該是目前佔有率最高的TSDB了,因此我們利用InfluxDB來了解TSDB的運作。
這裡是InfluxData的官網,其open source的版本中有一個TICK stack的架構,包含了四個元件:
- Telegraf:資料收集元件
- InfluxDB:資料儲存元件
- Chronograf:視覺化操作介面
- Kapacitor:資料處理引擎
為熟悉InfluxDB,我們透過關聯式資料庫的概念來了解一下InfluxDB的架構。你也可以透過官網的Key concepts來做更深入的了解。
- database:這個概念跟關聯式資料庫一樣
- measurement:相當於表格(table)
- tag:有索引的欄位 (indexed column)
- field:沒有索引的欄位 (non-indexed column)
先提這四個名詞。如果各位想了解更多詞彙,可以參考官網上的Glossary。
為了快速達到了解InfluxDB,我們只先專注在InfluxDB與Chronograf。首先先來安裝這兩個元件。我們以Windows為使用環境。請先到官網的下載頁面進行下載。

下載的是zip格式檔案,只要將之解壓縮即可。我們先來看influxdb.zip,解開後會有5個exe執行檔。主要的有兩個:influxd.exe是InfluxDB server,執行起來後可以看到這樣的畫面。server預設會使用port 8086來接收API指令。因此系統的安全設定上要允許使用這個port。資料庫預設的username及password都是root。

influx.exe 是client程式,我們可以利用這個程式來操作資料庫。直接執行後便可以連接到本機上資料庫。我們可以先試一個指令 "show databases" 來看看資料庫是否正常運作。如果有回應目前資料庫中databases清單,便表示系統正常運作。 (由於才剛剛安裝,應該只有 _internal 這個內部資料庫)

我們可以用exit指令來離開client程式。
InfluxDB使用的query language是InfluxQL,官網上有一頁做了與SQL的比較,大家可以參考一下。
接下來解開chronograf.zip後,有兩個exe。chronograf.exe是web server程式。執行後以瀏覽器連接 http://localhost:8888,就可以進入到視覺化界面。

我們可以先到configuration頁面檢視目前與InfluxDB server的連線狀況

到目前InfluxDB與Chronograf都完成安裝並可以正常執行。要停止這兩個server的執行,只要按ctrl-C即可。
下一篇,我們將寫個Python程式來為資料進資料庫,並在Chronograf中設定dashboard的圖表。
2019/01/14
時間序列資料與資料庫
再資料處理領域中,有一類型的資料是跟時間有密切關係的,這類的資料紀錄了某事物隨著時間變動的狀態,例如某商品的價格資訊、某廠房的環境溫溼度、某物流車的位置與速度等等。這些資料都屬於時間序列資料(Time-Series Data)。
這類型的資料有一些特質:
資料若要利用資訊系統來處理,儲存便是一個重要的課題。目前許多的應用中,會使用關聯式資料庫加上一個time-stamp欄位來解決這問題。若檢視時間序列資料的特質,我們要考量的因素有:
下一篇,我們將開始安裝與使用InfluxDB。
這類型的資料有一些特質:
- 資料是用時間排序的一組隨機變量,例如下圖,數值會隨著時間的變化而改變,因此時間是很重要的資料維度之一

- 資料的產生可能是快速、大量且持續
例如某個機台,每秒鐘會產生100筆資料,每筆資料約250KB,一天下來單單一個機台的資料量就高達2TB了,而且只要生產線保持運作,資料就不斷的產生

資料若要利用資訊系統來處理,儲存便是一個重要的課題。目前許多的應用中,會使用關聯式資料庫加上一個time-stamp欄位來解決這問題。若檢視時間序列資料的特質,我們要考量的因素有:
- 資料是源源不斷產生,而且鮮少需要修改,因此insert的效能會是重要因素,update反而不那麼重要
- 在一些應用中,資料的產生是快速且大量的,因此擴展性(scalability)就相當重要
- 時間的運算常會是取回資料時常用到的功能,所以時間運算的效能很重要
下一篇,我們將開始安裝與使用InfluxDB。
訂閱:
文章 (Atom)